Парсер РФ

Данные часто называют новой нефтью. Однако, как и нефть, они должны быть обработаны, чтобы иметь большую ценность. С помощью парсинга данных мы можем преобразовывать их в различные форматы. Это, в свою очередь, делает их доступными для более широкого спектра приложений. Давайте рассмотрим, как это работает. Отказ от ответственности: данный материал подготовлен строго в информационных целях. Он не является одобрением какой-либо деятельности (в том числе незаконной), продуктов или услуг. Вы несете полную ответственность за соблюдение действующего законодательства, включая законы об интеллектуальной собственности, при использовании наших услуг или полагаясь на любую информацию, содержащуюся здесь.
Парсер РФ: Что такое парсинг данных?
Парсинг данных или парсер рф (российский парсер) - это процесс преобразования данных из одного формата в другой. Это критически важный процесс в управлении данными. Парсинг делает данные более доступными и облегчает работу с ними. Это как перевод иностранного языка на ваш родной. Перевод делает контент доступным для гораздо более широкой аудитории. Такая доступность придает языку большую ценность.
Как работает парсинг данных?
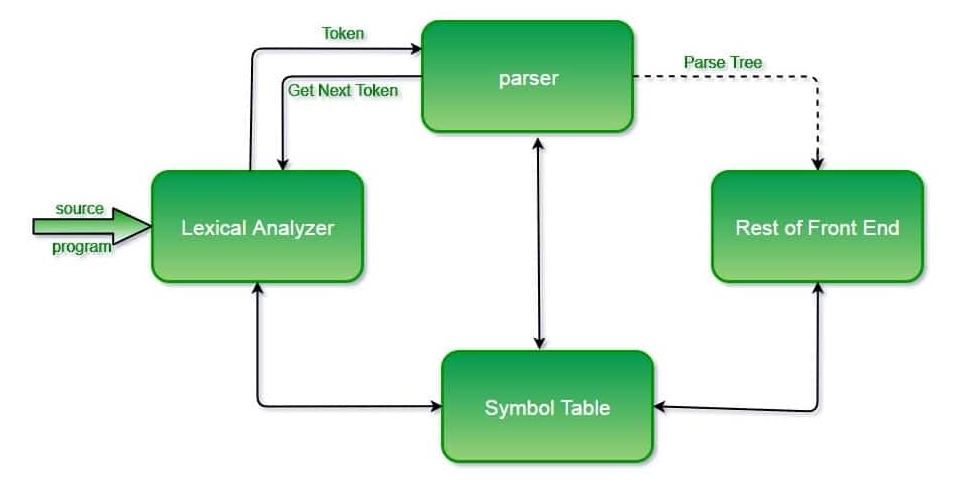
Парсеры работают по-разному в зависимости от структуры данных, с которыми им приходится работать. По своей сути парсинг данных упрощает сложные структуры данных. Это упрощение позволяет извлекать и использовать нужную информацию. Это похоже на разбиение большой головоломки на более мелкие и легко понятные части.
Парсер РФ: Разбивка процесса парсинга данных
Получение данных: На первом этапе необходимо получить доступ к данным, которые нужно спарсить. Эти данные могут храниться в файле, быть получены от других пользователей или взяты из интернета. Для последнего варианта – предпочтительнее использовать скрапер с прокси.
Создание структуры: Парсер РФ изучает входные данные, чтобы определить их формат и структуру. Это может включать в себя распознавание шаблонов, разделителей (например, запятых в CSV-файлах) или определенных тегов в XML/HTML-документах.
Преобразование данных: После определения структуры алгоритм синтаксического анализа преобразует данные в нужный формат. Это может означать превращение строки JSON в словарь Python или извлечение информации с веб-страницы в структурированную базу данных. Формирование выходных данных: Последний шаг - вывод преобразованных данных в более подходящий формат для хранения, анализа или дальнейшей обработки.
Парсинг РФ: Типы форматов данных, которые обычно анализируются
Специалисты по работе с данными могут адаптировать свои стратегии парсинга, понимая характеристики и области применения этих форматов. Они могут удовлетворить потребности своих проектов, обеспечив эффективный и результативный анализ данных.
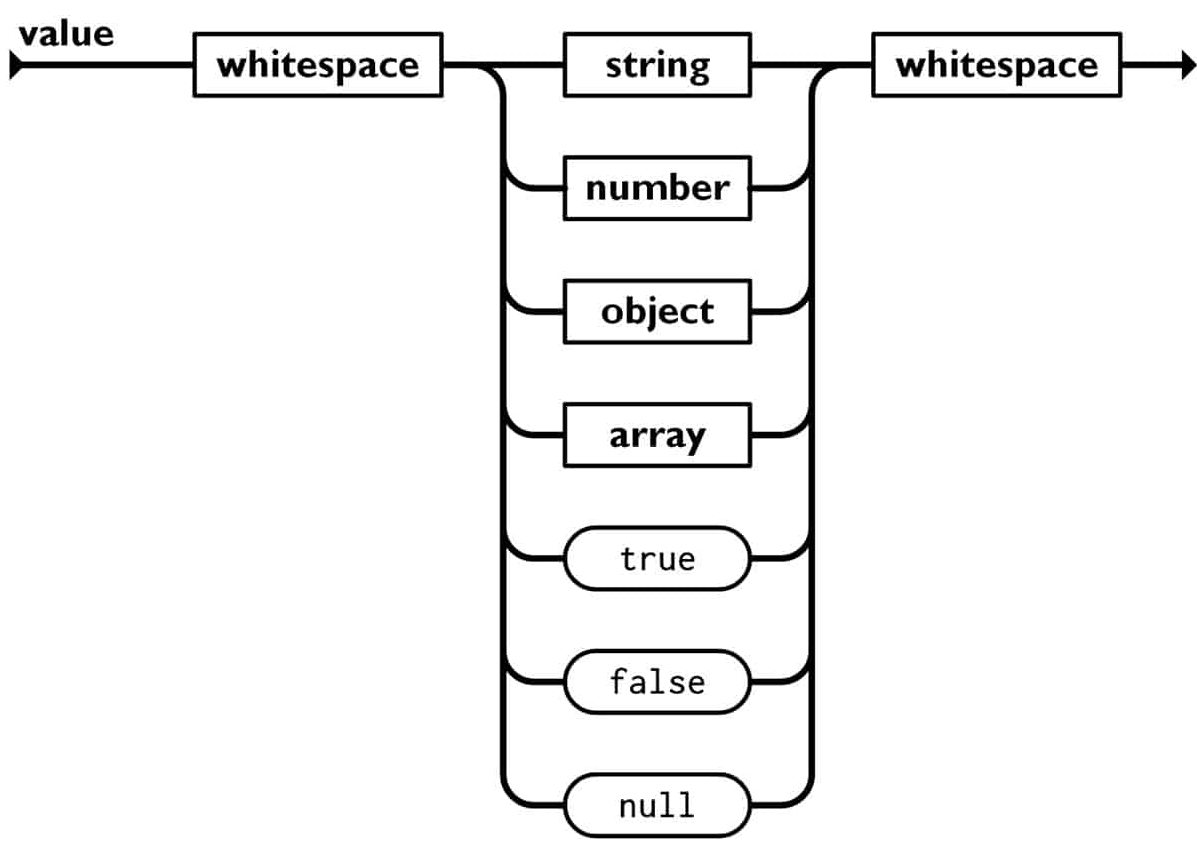
(данные JSON обычно легко парсятся благодаря своей простой структуре)
Структурированные данные в конкретном формате, что облегчает их анализ и обработку. Такие форматы предсказуемы и просты для парсинга и редактирования с помощью стандартных инструментов программирования. К примеру как это можно сделать:
• EXtensible Markup Language: XML широко используется для хранения и передачи данных. Он высокоструктурирован, имеет формат, основанный на тегах, который позволяет определять пользовательские теги, что делает его универсальным для различных приложений.
• JavaScript Object Notation: Известный своей легкой и текстовой структурой, JSON идеально подходит для обмена данными между серверами и веб-приложениями. Его простой для понимания формат, напоминающий объектные литералы JavaScript, делает его любимым среди веб-разработчиков.
• CSV: Файлы CSV, обычно известные как «формат Excel», представляют данные в табличной форме. В них просто используются запятые для разделения значений. Этот формат широко широко используется для электронных таблиц и баз данных.
Форматы неструктурированных данных
Неструктурированные данные не имеют определенного формата или структуры, что создает более серьезные трудности при их парсинге. При работе с неструктурированными данными часто используются более сложные процессы, такие как регулярные выражения. Например:
• Текстовые файлы: Обычные текстовые файлы содержат данные без определенной структуры, поэтому для извлечения значимой информации на основе шаблонов или ключевых слов часто требуется специальная логика синтаксического анализа.
• Веб-страницы: HTML-документы - яркий пример неструктурированных данных, с которыми можно работать для парсинга информации. Такие инструменты, как веб-скраперы, ориентируются в иерархической структуре HTML-тегов, чтобы извлечь конкретные данные.
Форматы полуструктурированных данных
Форматы полуструктурированных данных содержат характеристики как структурированных, так и неструктурированных данных. Они не имеют жесткой схемы, как структурированные данные, но обладают идентифицируемыми шаблонами, облегчающими процесс преобразования. Для примера:
• Электронные письма: Хотя тело письма может быть неструктурированным текстом, заголовки и метаданные имеют последовательный формат, который можно парсить.
• Журналы: Системные журналы или журналы приложений обычно имеют полуструктурированный формат, в котором каждая запись представляет собой неструктурированный текст, но соответствует последовательной схеме, что делает возможным систематический анализ данных журнала.
Парсер РФ: Примеры инструментов для парсинга данных
Для парсинга данных существует множество инструментов. Некоторые из них являются самостоятельными, а другие существуют в экосистемах разработки. Вот несколько примеров наиболее популярных инструментов:
• Logstash: Конвейер обработки данных на стороне сервера, который одновременно получает данные из нескольких источников. Logstash преобразует их, а затем отправляет в «тайник», например Elasticsearch. Он полезен для парсинга журналов и других данных, основанных на времени, предлагая фильтры, которые могут парсить и преобразовывать данные перед их индексацией.

• Apache NiFi: Интегрированная платформа логистики данных для автоматизации перемещения данных между разрозненными системами. NiFi поддерживает различные функции преобразования данных, что делает ее подходящей для сложных потоков данных.
• OpenRefine: Ранее известный как Google Refine. OpenRefine отлично подходит для работы с беспорядочными данными. Он может очищать данные и преобразовывать их из одного формата в другой.
• XPath и XQuery: Являясь частью экосистемы XML, эти функции анализируют и запрашивают XML-документы. Они необходимы для сценариев, в которых требуется эффективная навигация и извлечение XML-данных.
Реальные применения парсинга данных
Парсинг данных выходит за рамки обработки данных, затрагивая различные аспекты бизнес-операций, исследований и повседневного использования технологий. Вот несколько практических приложений, в которых парсинг данных играет ключевую роль:
• Веб-скрапинг: Извлечение данных с веб-страниц является квинтэссенцией парсинга данных. Он широко используется для исследования рынка, анализа конкурентов, мониторинга цен и агрегирования информации из различных онлайн-источников.
• Обработка естественного языка: NLP - это область искусственного интеллекта, которая в значительной степени опирается на синтаксический анализ для понимания человеческого языка. Она может применяться во всем: от анализа настроений до чат-ботов и перевода иностранных языков.
• Анализ файлов журналов: Позволяет извлекать необходимую информацию из журналов. Данные часто имеют полуструктурированный формат. Организации анализируют эти файлы, чтобы следить за состоянием системы, выявлять аномалии и оптимизировать производительность.
• Анализ финансовых данных: Парсинг позволяет обрабатывать и анализировать огромные объемы финансовых данных. Он позволяет финансовым аналитикам преобразовывать необработанные данные в формат, пригодный для анализа тенденций, оценки рисков и алгоритмической торговли.
• Научные исследования: Помогает исследователям собирать и анализировать данные исследований. Область применения широка и охватывает все: от результатов экспериментов до анализа больших массивов данных.
Парсер для РФ: Общие проблемы и способы решения
Несмотря на свою незаменимость, анализ данных также сопряжен с определенными трудностями. Эти проблемы могут усложнить процесс и повлиять на результат. Понимание этих трудностей крайне важно для всех, кто работает с данными. Вот некоторые распространенные проблемы и их влияние на процесс парсинга:
• Работа с большими массивами данных: Работа с массивными файлами или потоками данных может привести к узким местам в производительности, требуя значительных вычислительных ресурсов. Эффективное управление памятью и методы парсинга потоковых данных очень важны.
• Работа со сложными структурами данных: Парсинг таких структур требует понимания иерархии и взаимосвязей внутри данных. Для решения этой проблемы необходимо разработать логику синтаксического анализа, позволяющую ориентироваться в этих сложных структурах без потери контекста.
• Качество и согласованность данных: Эти проблемы могут помешать процессу парсинга, что приведет к неточным или неполным наборам данных. Реализация надежных механизмов обработки ошибок и проверки данных имеет решающее значение для их выявления и устранения.
• Редкие и новые форматы данных: Форматы данных имеют тенденцию к развитию. Это требует обновления алгоритмов синтаксического анализа для учета новых структур и особенностей.
• Кодировка и язык: Эти факторы могут усложнить процесс парсинга, особенно если речь идет о глобальных наборах данных. Убедиться, что в процессе парсинга соблюдается кодировка, очень важно, чтобы избежать повреждения данных или потери смысла. • Оптимизация производительности: Быстрые алгоритмы парсинга могут упустить нюансы в данных, в то время как высокоточные методы могут быть ресурсоемкими. Поиск правильного баланса требует глубокого понимания данных и целей процесса парсинга.

Парсер РФ: Лучшие практики парсинга данных
Чтобы справиться со сложностями парсинга данных и добиться его максимальной эффективности, необходимо придерживаться определенных передовых методов. Эти рекомендации помогут преодолеть общие проблемы и обеспечить целостность и удобство использования спарсенных данных.
• Поймите свои данные: Предварительный анализ может помочь вам в выборе инструментов и методов парсинга. Это обеспечит хорошее соответствие поставленной задаче.
• Выберите правильные инструменты: Инструменты парсинга часто обладают уникальными характеристиками. Например, Python's BeautifulSoup отлично подходит для парсинга HTML, а Pandas отлично справляется со структурированными файлами данных.
• Реализуйте обработку ошибок: Надежные механизмы крайне важны для решения проблем, связанных с несоответствиями, отсутствующими значениями или неожиданными форматами данных. Вы можете регистрировать их для дальнейшего анализа.
• Валидация и очистка данных: Это может включать проверку соответствия типов данных, а также удаление или исправление. Этот процесс делает данные более надежными и удобными для анализа.
• Оптимизация производительности: Такие методы, как параллельная обработка, позволяют значительно сократить использование памяти и ускорить парсинг данных.
• Управление кодировками: Вы можете предотвратить повреждение данных, учитывая различные кодировки и наборы символов. Это также гарантирует, что спарсенные данные точно отражают исходное содержимое. • Документируйте процесс: Документация помогает в устранении неполадок, будущих обновлениях и совместной работе.

Заключительные мысли
Парсер рф (для российских сайтов) – с его помощью можно колоссально облегчить работу современном мире, основанном на данных. Если вы аналитик данных, разработчик программного обеспечения или просто интересуетесь данными, понимание и освоение парсинга может быть невероятно полезным. Учитывая широкую сферу применения, вряд ли в ближайшее время мы прекратим заниматься парсингом данных. Как вы уже знаете, он помогает компаниям принимать обоснованные решения, повышает эффективность операций и способствует инновациям в области технологий и исследований.
А, если вы хотите в два клика парсить любой формат данных, то регистрируйтесь в нашем сервисе PartScanner и получите две недели парсинга абсолютно бесплатно.
 Чат
поддержки
Чат
поддержки