Текстовый парсер или как парсить любые данные не вставая с дивана!

Парсинг данных - это термин, который часто встречается при работе с большими объемами данных, особенно для тех, кто занимается сбором данных из Интернета, а также для инженеров-программистов. Однако парсинг данных - это тема, которая нуждается в более глубоком обсуждении. Например, что именно представляет собой парсинг данных и как его реализовать в реальном мире.
В этой статье мы ответим на все эти вопросы и введём вас в курс основных терминов, связанных с парсингом данных.
Текстовый парсер: Что означает парсинг в целом?
Когда вы извлекаете большое количество данных с помощью веб-скраппинга, они находятся в формате HTML. К сожалению, это не тот формат, который может прочитать любой не программист. Поэтому необходимо проделать дополнительную работу с данными, чтобы привести их в человекочитаемый формат, удобный для анализа специалистами. Именно текстовый парсер выполняет большую часть этой тяжелой работы по парсингу данных.
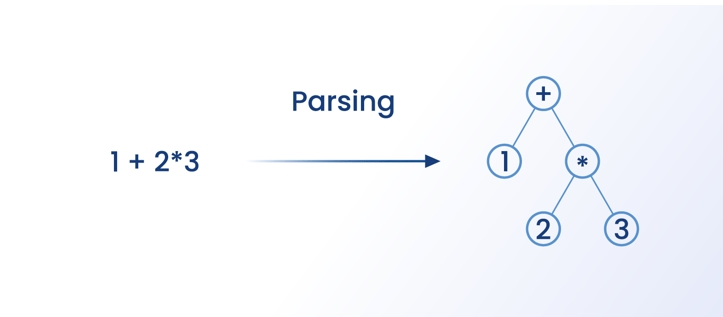
Что делает текстовый парсер?
Текстовый парсер преобразует данные из одного формата в другой. Например, парсер преобразует HTML-данные, полученные с помощью скраппинга, в JSON, CSV и даже в табличные данные, чтобы их можно было читать и анализировать. Парсер не парсит каждую строку HTML, потому что хороший парсер спарсит нужные данные из HTML-тегах.
Различные технологии, использующие парсер
Как уже говорилось в предыдущем разделе, поскольку парсер не привязан ни к одной конкретной технологии, он исключительно гибок по своей природе. Поэтому он используются в самых разных целях:
Языки сценариев - это языки, для выполнения которых не требуется компилятор, поскольку они запускаются на основе серии команд в файле. Типичными примерами являются PHP, Python и JavaScript.
Java и другие языки программирования. Языки программирования высокого уровня, такие как Java, используют компилятор для преобразования исходного кода в язык ассемблера. Важным компонентом этих компиляторов является парсер, который создает внутреннее представление исходного кода.
HTML и XML - в случае с HTML - парсер извлекает текст из HTML-тегов, таких как заголовки, подзаголовки, абзацы и т. д. В то время как парсер XML - это библиотека, которая облегчает чтение и управление XML-документами.
Языки SQL и базы данных - парсер SQL, например, анализирует SQL-запрос и генерирует поля, определенные в SQL-запросе.
Языки моделирования - парсер в языках моделирования позволяет разработчикам, аналитикам и заинтересованным сторонам понять структуру моделируемой системы. • Языки интерактивных данных - используются для интерактивной обработки больших объемов данных, в том числе в космической науке и физике Солнца.
Текстовый парсер: Зачем нужен парсинг данных?
Основная причина необходимости парсинга (синтаксического анализа) заключается в том, что различным организациям требуются данные в разных форматах. Таким образом, синтаксический анализ позволяет преобразовать данные так, чтобы их мог понять человек или, в некоторых случаях, программное обеспечение. Одним из ярких примеров последнего являются компьютерные программы. Сначала люди пишут их в понятном им формате на языке высокого уровня, аналогичном естественному языку вроде русского, которым мы пользуемся ежедневно. Затем компьютеры переводят их в форму, вплоть до машинного кода, которую компьютеры понимают. Парсинг также необходим в ситуациях, когда требуется взаимодействие между двумя различными программами - например, сериализация и десериализация класса.
Терминология парсинга и структура парсера
До этого момента вам были известны фундаментальные понятия синтаксического анализа данных. Теперь пришло время изучить основные понятия, связанные с парсингом данных, и то, как работает парсер.
Терминология

Регулярные выражения
Регулярные выражения - это выглядит в виде формулы. Чаще всего они используются в языках высокого уровня и скриптовых языках для проверки адреса электронной почты или даты рождения. Хотя они считаются непригодными для парсинга данных, их все же можно использовать для парсинга простого ввода. Это заблуждение возникает из-за того, что некоторые программисты используют регулярные выражения для каждой задачи синтаксического анализа, даже когда они не должны использоваться. В таких случаях в результате получается ряд регулярных выражений, собранных вместе. Вы можете использовать регулярные выражения для парсинга некоторых простых языков программирования, также известных как регулярные языки. Однако это не относится к HTML, который можно считать простым языком. Это связано с тем, что внутри HTML-тегов можно встретить любое количество произвольных тегов. Кроме того, согласно его грамматике, в нем есть рекурсивные и вложенные элементы, которые нельзя отнести к регулярным языкам. Поэтому вы не сможете парсить их правильно.
Грамматика
Грамматика - это набор правил, которые описывают язык синтаксически. Таким образом, она относится только к синтаксису, но не к семантике языка. Другими словами, грамматика относится к структуре языка, а не к его значению. Рассмотрим следующий пример: HI: «Привет» ИМЯ: [a-zA-z] + Приветствие: Привет ИМЯ Двумя возможными приветствиями для приведенного выше куска кода могут быть «Привет, Сергей» или «Привет, Код». С точки зрения структуры языка оба варианта верны. Однако во втором случае, поскольку «Код» не является именем человека, оно неверно с семантической точки зрения.
Анатомия грамматики
Мы можем рассмотреть анатомию грамматики с помощью общепринятых форм, таких как форма Бэкуса-Наура (БНФ). У этой формы есть свои варианты, например, расширенная форма Бэкуса-Наура, которая указывает на повтор. Другой вариант БНФ - дополненная форма Бэкуса-Наура. Она используется при описании двунаправленных коммуникационных протоколов. Когда вы используете типичное правило в форме Бэкуса-Наура, оно выглядит следующим образом: : : _expression_ является нетерминальным, что означает, что вы можете заменить его элементами справа, _expression_ _expression_ может содержать как терминальные, так и нетерминальные символы. Теперь вы можете спросить, что такое терминальные символы? Это те, которые не встречаются в качестве символов ни в одном из компонентов грамматики. Типичным примером терминального символа является строка символов, например «Program». Поскольку правило, подобное приведенному выше, технически определяет преобразование между нетерминалом и группой нетерминалов и терминалом справа, его можно назвать производящим правилом.
Типы грамматик
Существует два типа грамматик: регулярные грамматики и контекстно-свободные грамматики. Регулярные грамматики используются для определения общего языка. Существует также более современный тип грамматик, известный как Parsing Expression Grammar (PEG), представляющий контекстно-свободные языки, и они также являются мощными контекстно-свободными грамматиками. В любом случае разница между этими двумя типами зависит от нотации и способа реализации правил. Проще всего отличить две грамматики по _expression_, или правой части правила, которое может иметь вид : • Пустая строка • Одиночный терминальный символ • За одним терминальным символом следует нетерминальный символ. В реальности это легче сказать, чем сделать, потому что конкретный инструмент может разрешить больше терминальных символов в одном определении. Тогда он может преобразовать выражение в правильную серию выражений, которая относится к любому из вышеперечисленных случаев.
Компоненты синтаксического анализатора

Поскольку синтаксический анализатор отвечает за анализ строк символов на языке программирования, соответствующей правилам грамматики, которые мы только что обсудили, мы можем разбить функциональность синтаксического анализатора на два этапа. Обычно парсеру поручают программно прочитать, проанализировать и преобразовать неструктурированные данные в структурированный формат. Два основных компонента, составляющих парсер, - это лексический и синтаксический анализ. Кроме того, некоторые парсеры также реализуют компонент семантического анализа, который принимает структурированные данные и фильтрует их как: положительные или отрицательные, полные или неполные. Хотя вы можете предположить, что этот процесс еще больше улучшает процесс анализа данных, это не всегда так. Семантический анализ не встроен в большинство парсеров из-за более практики семантического анализа человеком. Далее обсудим два основных процесса работы парсера.
Лексический анализ
Его выполняют парсеры, которые также называют сканерами или токенизаторами, и их роль заключается в преобразовании последовательности необработанных неструктурированных данных или символов в токены. Часто строка символов, поступающая в парсер, имеет формат HTML. Затем парсер создает лексемы, используя лексические единицы, включая ключевые слова, идентификаторы и разделители. Одновременно парсер игнорирует лексически нерелевантные данные, о которых мы говорили во вступительном разделе. Например, это пробелы и комментарии в HTML-документе. После того как синтаксический анализатор отбрасывает нерелевантные лексемы в ходе лексического анализа, остальная часть процесса синтаксического парсинга занимается синтаксическим анализом.
Синтаксический анализ
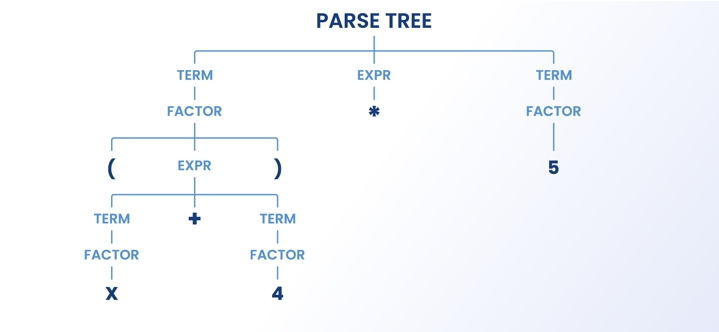
Эта фаза синтаксического анализа заключается в построении дерева парсинга. Это означает, что после создания лексем синтаксический анализатор упорядочивает их в дерево. Во время этого процесса нерелевантные лексемы также попадают в структуру вложенности самого дерева. К нерелевантным лексемам относятся скобки, точки с запятой и фигурные скобки. Чтобы вы лучше поняли это, давайте проиллюстрируем это простым математическим уравнением: (a*2)+4 Лексика синтаксического анализатора разделит их на лексемы следующим образом:
( => Parenthesis
a => Value
* => Multiply
2 => Value
)=> Parenthesis
+ => Plus
4 => Value
После этого дерево парсинга будет построено следующим образом:
Текстовый парсер: собственный или аутсорсинговый?
Теперь вы получили представление о фундаментальных аспектах парсера. Настало время для волнующего аспекта: создать свой парсер или прибегнуть к услугам сторонней организации. Для начала давайте рассмотрим плюсы и минусы каждого метода.

Плюсы собственного парсера
При создании собственного парсера вы получаете множество преимуществ. Одно из главных преимуществ - это возможность контролировать его возможности. Кроме того, поскольку парсеры не ограничены каким-либо одним форматом данных, у вас есть возможность настроить его под различные форматы данных. Среди других существенных преимуществ - экономия средств и контроль над обновлением и поддержкой вашего парсера.
Минусы собственного парсера
Собственный парсер не лишен недостатков. Одним из существенных недостатков является то, что он будет отнимать много вашего драгоценного времени, в то время как вы тратите много времени на его обслуживание, обновление и тестирование. Другой недостаток заключается в том, сможете ли вы купить или арендовать мощный сервер, чтобы парсить все данные быстрее, чем вам требуется. И наконец, вам придется обучать весь свой штат сотрудников, чтобы создать собственный парсер и проводить обучение по работе с ним.
Плюсы парсера на аутсорсинге
При аренда парсера вы сэкономите деньги, которые тратите на человеческие ресурсы, поскольку компания обеспечит вас всеми возможностями, включая серверы и сам парсер. Кроме того, вы с наименьшей вероятностью столкнетесь с критическими ошибками, поскольку компания, создавшая парсер, будет занята преждевременным устранением ошибок. Если возникнет какая-либо ошибка, техническая поддержка быстро решит эту проблему.
Минусы парсера на аутсорсе
Хотя аутсорсинг имеет множество преимуществ, у него есть и отрицательные стороны. Основные недостатки заключаются в возможности кастомной настройки и стоимости. Поскольку компания, занимающаяся парсингом, создала весь функционал под себя, некоторых нужных вам функций может и не быть. Кроме того, ваш полный контроль над парсером будет ограничен.
Заключение
Из этой объемной статьи вы узнали о том, как работает парсер в целом и текстовый парсер в частности, о процессе парсинга данных в целом и его основах. Парсинг данных - это долгий и сложный процесс. Но вы можете уже сейчас воспользоваться нашим сервисом Partscanner в течении двух недель абсолютно бесплатно!
Добавить комментарий
Ваш адрес email не будет опубликован. Обязательные поля помечены *
0 Комментариев