Что такое парсер parser простыми словами? И зачем он нужен именно вам?

Когда люди слышат слово «веб-скраппинг», в их сознании возникает мысль о том, что они извлекают данные с веб-страниц. Но эти люди не знают, что основная часть работы заключается не в тупом скачивании подчистую всей веб-страницы, а в извлечении нужных вам данных, а это делается с помощью парсинга данных.
Это происходит потому, что для загрузки веб-страницы достаточно отправить HTTP GET-запрос, и вся страница будет спарсена для вас. Даже из структурированных страниц сложно извлечь данные, не встроенные в собственный HTML-тег, а объединенные с другими большими фрагментами текста. Как вы вычлените такие данные из онлайн-форумов, где они расположены не в определенных тегах и областях, которые вы можете легко выделить с помощью селекторов CSS? Если вы хоть немного разбираетесь в веб-скрапинге, то знаете, что это одна из самых сложных задач.
Что такое парсер (parser) и парсинг данных?
Термин «парсинг данных» имеет множество областей, в которых он может применяться даже в компьютерных науках. Для тех, кто занимается веб-скраппингом и скринскраппингом, парсинг данных - это процесс извлечения нужных данных из большой строки текста, которая может быть веб-страницей, PDF или любым текстовым файлом.
Техники парсинга данных
Форматы файлов многочисленны как и языки программирования, поэтому для разных случаев доступны разные инструменты. Давайте рассмотрим некоторые из популярных форматов файлов и способы извлечения данных из них.
Парсинг HTML-документов
Самым популярным для парсинга являются веб-страницы. Если раньше веб-страницы существовали и в других форматах, то сейчас в тренде HTML. Большинство людей, занимающихся веб-скраппингом, вынуждены разбирать HTML-файлы, чтобы получить необходимые данные. Если вы собираетесь парсить HTML- или XML-документы, у вас есть два варианта - использование библиотеки или regex-выражения.
Использование библиотеки парсинга
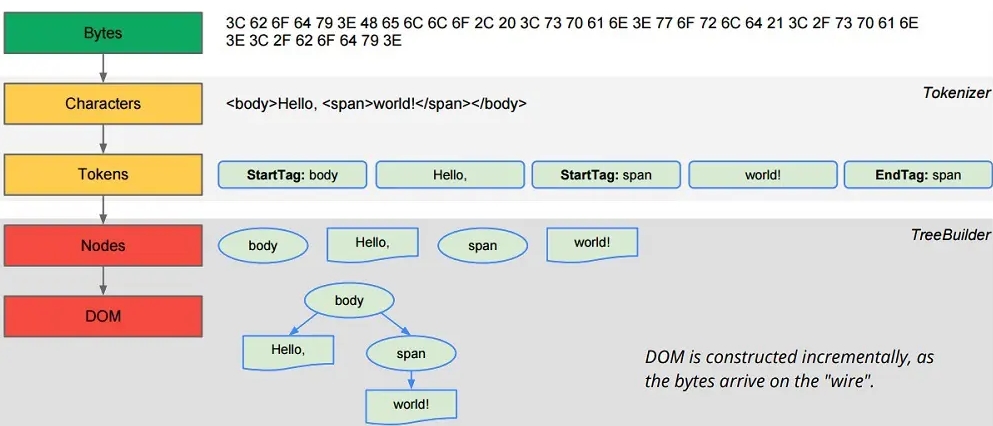
Самый простой способ спарсить данные из HTML-документа - использовать библиотеку. Почему бы не использовать доступные вам сторонние библиотеки. Библиотеки для парсинга преобразуют документ в структуру DOM, чтобы вы могли получить доступ к данным через их теги, классы и ID, а также другие CSS-селекторы. Большинство из этих библиотек бесплатны даже для коммерческого использования. Выбор библиотеки зависит от языка программирования.
Например, программисты на Python могут использовать BeautifulSoup для парсинга HTML-документов - BeautifulSoup является чисто библиотекой для парсинга. BeautifulSoup - это самый простой вариант, доступный программистам на Python. Они могут использовать ее для доступа к любым данным в HTML- или XML-документах. Scrapy - еще один инструмент, используемый программистами на Python, но, в отличие от BeautifulSoup, это не библиотека парсинга, а фреймворк для веб-скрапинга, включающий в себя парсинг данных.
Scrapy и Beautifulsoup в качестве парсера (parser)

Для Javascript вам не нужен сторонний парсер (parser), так как вы можете парсить с помощью этого прекрасного языка программирования напряму. Однако некоторые пользователи для простоты все еще используют такие парсеры, как Cheerio. Разработчики Java могут использовать JSoup, а разработчики C# - AngleSharp.
Использование регулярных выражений
Библиотека регулярных выражений (regex) - это инструмент, используемый для парсинга данных путем сопоставления шаблонов в тексте.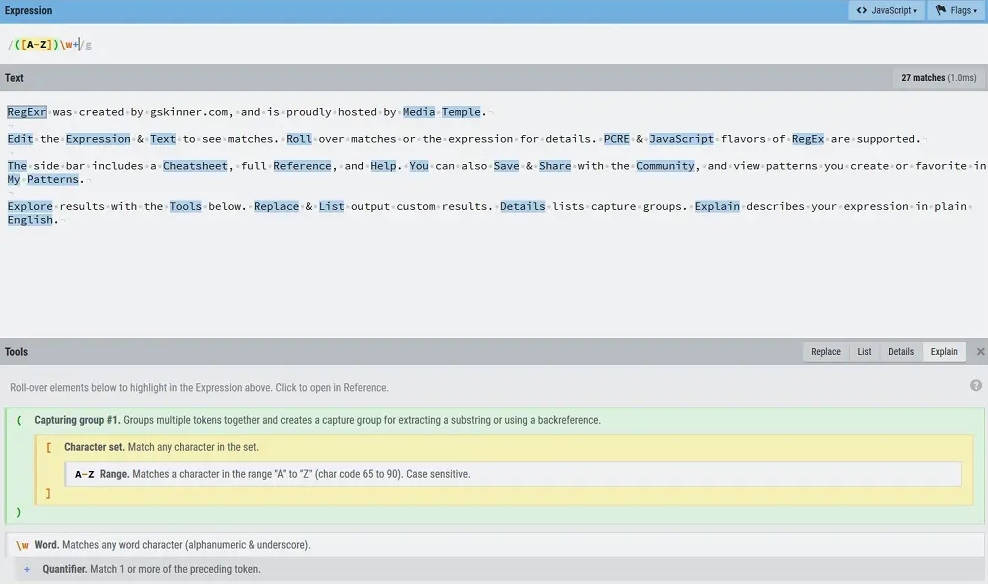
Большинство языков поддерживают regex, чтобы узнать больше о regex для вашего конкретного языка, посетите сайт regex.
Парсинг PDF-документа
У многих компаний есть данные, которые они хотели бы извлечь из PDF-документов. В такой ситуации необходимо воспользоваться библиотекой PDF, чтобы иметь возможность спарсить нужные данные. Разработчики на Python могут воспользоваться такими инструментами, как asPyPDF2 и PDFQuery. Другие языки программирования имеют свои собственные инструменты, которые можно использовать.
Парсинг текстовых файлов
Когда мы говорим о текстовых файлах, то имеет в виду файлы с расширением .txt. Это могут быть и другие текстовые форматы например. Когда вы сталкиваетесь с проблемой парсинга данных из неструктурированных текстовых файлов, вам необходимо использовать регулярные выражения.
Заключение
А, если вы хотите в два клика парсить любой формат документов, то регистрируйтесь в нашем сервисе PartScanner и получите две недели парсинга абсолютно бесплатно.
Добавить комментарий
Ваш адрес email не будет опубликован. Обязательные поля помечены *
0 Комментариев